
Figure 1.0: Actor in bird costume holding the letter ‘H’
Independent study research project by Greg Slepak
Version 2.0.0 - See document history.
For my independent study I decided to research a fairly recently developed artificial intelligence concept known as Hierarchical Temporal Memory (HTM). I was delighted when Dr. Dankel agreed to oversee my project, as I greatly respect him and he has years of experience teaching artificial intelligence concepts.
The goal of my independent study was to learn about the HTM and, if time allowed, create my own implementation and test it. As I delved into the subject, however, it became apparent that there simply would not be anywhere near the necessary amount of time to create an implementation, so I decided to settle for a basic understanding.
This document contains an account of my research and present understanding of the HTM, as well as a brief history of the concept.
The first public mention of the HTM I was able to find appears to be from Jeff Hawkins’ book, On Intelligence.
After leaving Palm, Inc., Hawkins continued a personal quest he began decades before: to invent a general theory that explains how the brain works. Together with Donna Dubinsky and Dileep George, he founded Numenta Incorporated in March of 2005.1 Later on, Numenta renamed itself to Grok in order to emphasize its transition from a research-based company to a more product-oriented commercial venture. In this document, I will use the name Numenta when referring to Hawkins’ company because its use is still widespread and can be found throughout their documentation, source code, and employee email addresses.
The HTM builds upon artificial neural network (ANN) and Bayesian concepts that came before it2 (although you wouldn’t know this from Numenta’s documentation). Its novelty lies in its choice of topology and the way it chooses to incorporate and interpret modern models of the neocortex.
The best-laid plans of mice and men oft go awry 3
I originally planned to delve much deeper into this subject than I was able to. My hope was to create my own implementation of the HTM and test it on various input data, but for various reasons, detailed below, I was forced to settle for just a basic understanding of the concept.
Although the thought of implementing the HTM on my own might sound too ambitious for an independent study project, I thought that I might have a chance of doing it partly because I’d scheduled the course for Summer C, but mostly due to my own ignorance about the complexity that would be involved.
Had this independent study been the sole focus of my summer learning, I might have made some decent progress in that direction, especially when Numenta suddenly announced (this very summer) to open source their implementation. However, I had also signed up for two math courses that turned out to demand far more of my attention than I had anticipated (all of it). I struggled along with the math courses and ultimately decided to drop both of them halfway through Summer A. At that point, I hadn’t had a chance to spend any time on my independent study.
Dropping both math courses meant I had to arrange for another independent study course (math related) in order to fulfill my graduation requirements. Having thus obtained some free time, I immediately allocated a significant portion of it to another project.4
These developments, coupled with my responsibilities at home and at work, meant that I wouldn’t be able to complete my study of the HTM before the end of Summer C. Dr. Dankel was very kind and gracious enough to grant me an extension so that I could finish up this work before Fall classes began in full swing. For this, he has my sincerest gratitude and thanks.
As mentioned, Numenta released their implementation of the HTM and CLA as an open source project, calling it the Numenta Platform for Intelligent Computing, or NuPIC for short.
As wonderful as this news was, I quickly discovered that NuPIC contained many bugs, preventing it from simply compiling on many standard system setups, including mine.
Even worse, it turned out that Numenta had written NuPIC in C++ and Python!
I have well over a decade of experience writing software in C-based languages and consider myself to be an expert in the language and all its well known dialects. Of the “flavors of C” out there, I can say without hesitation that C++ is the absolute worst. I’d even go so far as to call C++ one of the worst programming languages ever invented by humankind, made all the worse due to its widespread use.
Linus Torvalds, mild-mannered father of three, husband of a a six-time Finnish national karate champion5, and author of the Linux kernel and the git version control system, had this to say about C++:
C++ is a horrible language. It’s made more horrible by the fact that a lot of substandard programmers use it, to the point where it’s much much easier to generate total and utter crap with it.
[..a portion his email removed for brevity..]
C++ leads to really really bad design choices. You invariably start using the “nice” library features of the language like STL and Boost and other total and utter crap, that may “help” you program, but causes:
infinite amounts of pain when they don’t work (and anybody who tells me that STL and especially Boost are stable and portable is just so full of BS that it’s not even funny)
inefficient abstracted programming models where two years down the road you notice that some abstraction wasn’t very efficient, but now all your code depends on all the nice object models around it, and you cannot fix it without rewriting your app.
A complete treatise on the tragedy that is C++ is beyond the scope of this document (and would make for an excellent dissertation), but needless to say, I believe Numenta’s decision to use it in NuPIC is a most unfortunate one. I suspect its costs will outweigh any perceived benefits they have in mind.
Prior to my involvement with NuPIC, I had not harbored any ill feelings toward Python. I later found out this was entirely due to my lack of exposure to it. I had never before worked in any serious capacity with the language, only occasionally modifying a script here and there.
On its surface, Python gives off the appearance of being an elegant—perhaps one could even say beautiful—programming language. This is due in part to the meaning it assigns to whitespace. Python code must look a certain way and follow very precise rules regarding whitespace, because tabs, spaces, etc., all have meaning in the language that can change how the program behaves.
This unorthodox decision, on the one hand, promotes a single concise and ubiquitous code style that all Python developers share. This can make it easier for programmers to read each other’s code and can also prevent potential quarrels from arising over who should be forced to change their coding style.
On the other hand, this decision comes at a price that can be experienced by anyone who has spent time sharing or copying Python code online. Web browsers, web forum software, and differences between editors, encodings, and operating systems can mangle the original formatting of the code, making it dead on arrival.
If that was Python’s only problem, Numenta’s decision to use it might not be so unfortunate. After all, Python’s syntax is fairly straightforward when compared with other languages, and might even deserve some praise.
Surprisingly, most of the issues I had with Python lay outside of the language itself, and had everything to do with its ecosystem. The majority of the problems I encountered attempting to build NuPIC and run its demos were, in fact, related to Python, not C++.
To start, Python does not have a good package manager for installing modules. At the moment pip appears to be the most popular package manager, and is the one used by NuPIC. However, pip is missing features commonly found in other package managers (like an info command to lookup information about a module), and failed to install dependencies for at least one module in NuPIC.
Python’s package managers cannot be fully blamed for their shortcomings and bugs. The real cause of many of the problems NuPIC had with its Python setup stem from design decisions related to how Python installs itself on systems and handles modules, as well as a long-standing schism in its versioning.
An in-depth dissection of Python’s ecosystem, folder hierarchy, and module system is also beyond the scope of this document, but I will attempt to briefly list some of the questionable design decisions in this area:
site-packages folder for each version of Python.
Python 3.x and 2.x are both being updated. Confusing “official advice” states:
Python 2.x is the status quo, Python 3.x is the present and future of the language
Isn’t the ‘status quo’ the present? Also:
Which version you ought to use is mostly dependent on what you want to get done.
This type of hand-wringing simply doesn’t exist in most other languages. There are typically very compelling reasons to keep up with the progress of the language, and developers who fail to do so can expect to get left behind.
site-packages folder is treated as a trash heap for all types random files:
PYTHONHOME, PYTHONPATH, PYTHONSTARTUP…Wtf is this?6
PYTHONPATH=$HOME/lib/pythonX.Y pythonX.Y setup.py install --install-lib=$HOME/lib/pythonX.Y --install-scripts=$HOME/bin ...and this?7
python setup.py install --home=~/python \
--install-purelib=lib \
--install-platlib='lib.$PLAT' \
--install-scripts=scripts \
--install-data=dataAbsolute insanity8:
Type of file Override option Python modules –install-purelib extension modules –install-platlib all modules –install-lib scripts –install-scripts data –install-data C headers –install-headers
This type of complexity simply isn’t necessary, as other languages and build-systems demonstrate.
A significant portion of my time was spent learning NuPIC’s build system and getting it to first compile, and then to run the examples.
For some reason, NuPIC’s repository contained not only the source code of its dependencies, but also binaries of various libraries and executables, one for each of the two platforms it supports (darwin64 and linux64). I don’t think I’ve ever seen that before. I spent a while changing the build scripts to not rely on these packaged dependencies and instead fetch them from an online repository using a package manager.
Once I got the project to compile successfully, the next few days were spent trying to get this test program to run successfully:
[prompt]$ $NTA/bin/htmtestNotice the bizarre use of environment variables in the command above. For some inexplicable reason the project’s README instructs developers to modify their bash configuration script to export several NuPIC-related environment variables:
Add the following to your .bashrc file. Change the paths as needed.
# Installation path export NTA=$HOME/nta/eng # Target source/repo path. Defaults to $PWD export NUPIC=/path/to/repo # Convenience variable for temporary build files export BUILDDIR=/tmp/ntabuild # Number of jobs to run in parallel (optional) export MK_JOBS=3 # Set up the rest of the necessary env variables. Must be done after # setting $NTA. source $NUPIC/env.sh
This also results in the alteration of the user’s PATH, PYTHONPATH, and LD_LIBRARY_PATH environment variables in a very arrogant (and simultaneously ignorant) fashion. These variables aren’t meant to be modified by a project. They exist as a convenience for users to modify the behavior of existing programs, and to customize their shell environment.
Worse, NuPIC exports several variables into the user’s environment, a practice that is generally frowned upon and referred to as “polluting” a user’s environment. There is no legitimate reason that any of this is necessary. I hope future versions of the software remove this behavior.
NuPIC’s README file claimed that it supported either Python 2.6 or 2.7, however I quickly discovered that this was not true. NuPIC’s htmtest failed to run for various reasons, and one of those was the fact that the project appeared to be untested with Python 2.7 and contained at least one critical hard-coded path reference to python2.6.
Instead of designing NuPIC in a generic fashion that would allow every part of it to dynamically find modules and dependencies at runtime, the project was designed to be compiled for a particular environment, making it impossible to create a portable library out of it that could be linked against and distributed with a program that made use of its features.
After fixing some of the issues I found with NuPIC’s build system, I submitted my modifications in a pull request and was asked to sign a Contributor’s License Agreement (CLA, not to be confused with the Cortical Learning Algorithm). Upon review, I noticed it contained a troubling sentence relating the granting of a patent license:
Subject to the terms and conditions of this Agreement, You hereby grant to Numenta and to recipients of software distributed by Numenta a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable (except as stated in this section) patent license to make, have made, use, offer to sell, sell, import, and otherwise transfer the Work, where such license applies only to those patent claims licensable by You that are necessarily infringed by Your Contribution(s) alone or by combination of Your Contribution(s) with the Work to which such Contribution(s) was submitted.
Unlike other types of literature, legal documents appear to encourage the use of run-on sentences, and therefore the reader can be forgiven if they don’t immediately see the very alarming scenario that sentence appears to allow for.
In brief, I let Numenta know that I couldn’t sign the agreement because:
[..] it appears to allow an interpretation that states that I’m potentially giving away royalty-free licenses to all the software patent claims I ever make should I make a single contribution to NuPIC, whatever it may be.
For a complete understanding of how such an interpretation is possible, please read part of the email exchange.
I was told that it was a word-for-word copy of the same section in the Apache CLA (v2) (a very common CLA with a long history of use), and therefore it would not be changed. However, after some additional poking, they brought up the issue with their legal team and discussed it internally. Eventually, they agreed to add a few clarifying words that would address the issue completely.
Of significance, Numenta announced the changes via their blog, and stated that they would allow existing contributors to sign the updated version. Matt Taylor, Numenta’s “Community Flag-Bearer”, explained the essence of what was clarified in the update:
This addition bounds the rights of Numenta, preventing us from exercising a royalty-free license to any patents a contributor creates in the future unassociated with the NuPIC project.
I am quite grateful for Matt’s help in addressing this issue. I have no doubt that his professionalism played an important role in Numenta’s decision.
Regarding the resolution, a good friend of mine remarked:
No small feat, getting a company to understand the implications of a contract its executives probably didn’t actually read closely in the first place, and then to send the document back to their lawyers to make it reasonable.
[..] a sympathetic stance would entail understanding that virtually no one reads this boilerplate stuff, that “bad code” gets passed along from one attorney and one organization to others, and then it gets defended for the surface-defensible reason that ‘standard contracts’ allow for legal interoperability. None of that sympathy is to endorse the going ‘standard’ – and it takes something like what [happened] to put things in better stead.
The fact that a fairly large and well known company took these steps to clarify the Apache CLA has significant consequences for the entire Open Source community.
In effect, Numenta’s actions legitimize the concerns that were raised, which sends a strong signal to every other company out there that uses the Apache CLA. It also sends a strong signal to every single developer who has ever signed a CLA that contains an identical (or similar) patent license clause.
The group most affected, however, are developers who have not yet signed an Apache-based CLA and have become aware of this issue (either through this paper or some blog post). The reason for this is that even if most companies would never abuse the CLA in the manner that the original language allows, the mere awareness of the possibility implies consent.
Why? Because if you are aware of the potential consequences that signing a legal document can have, and you still put your signature on it, then you cannot even use ignorance as a defense should the issue ever arise. That was the reason it became impossible for me to sign Numenta’s original CLA:
Given that multiple individuals now have (in written form) my understanding of what the document allows for, I cannot in good faith sign such a document as-is, because written as-is, it appears to allow an interpretation that states that I’m potentially giving away royalty-free licenses to all the software patent claims I ever make should I make a single contribution to NuPIC, whatever it may be.
At the time of publishing, the Apache CLA was at version 2.0. Hopefully, the Apache Foundation can amend their CLA in a future update.
In these sections we’ll give an overview of the essential concepts necessary to have a basic understanding of the HTM. We’ll also consider a few ways in which they compare with other types of artificial neural networks (ANNs). Some of the topics discussed in Numenta’s white paper, including reasons for various design decisions, performance considerations, etc., won’t be covered. Prior exposure to basic ANN concepts is assumed.
Figure 1.0: Actor in bird costume holding the letter ‘H’
The HTM has a hierarchical topology on account of hierarchies observed in some naturally occurring neural networks, such as those observed in the brain.
A hierarchical topology is also useful because it allows for the mapping of highly detailed (and possibly noisy) data, to progressively more stable and abstract concepts in the context of limited computer memory. The graphic below was taken from Numenta’s white paper and illustrates four HTM regions stacked on top of one another in a hierarchy. The aforementioned “noisy data” (pixels from a webcam, bits and bytes from an mp3, etc.) are fed into the bottom region of the hierarchy:
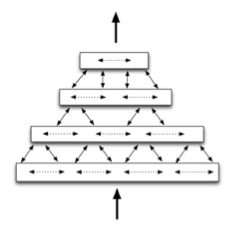
Figure 1.1: “Simplified diagram of four HTM regions arranged in a four-level hierarchy, communicating information within levels, between levels, and to/from outside the hierarchy”
An HTM can be composed of just one region, or several regions with data being fed through them. The region itself is comprised of interconnected cells that can be in one of three states:
The cells are stacked on top of each other in vertical columns forming a three dimensional grid:
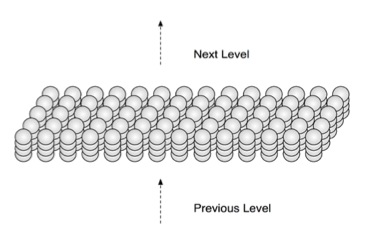
Figure 1.2: “This HTM region, including its columnar structure, is equivalent to one layer of neurons in a neocortical region.”
Recall that the purpose of a region is to map (potentially noisy) input-data to more stable abstract concepts. These “abstract concepts” actually have very non-abstract representations, namely the on or off state of cells within the region.
HTM regions have “sparse distributed representations”. Numenta’s whitepaper defines this term as follows:
“Sparse” means that only a small percentage of neurons are active at one time. “Distributed” means that the activations of many neurons are required in order to represent something. A single active neuron conveys some meaning but it must be interpreted within the context of a population of neurons to convey the full meaning. HTM regions also use sparse distributed representations.
I think the paper did a fine job explaining how this works in practice with the following example:
For example, a region might receive 20,000 input bits. The percentage of input bits that are “1” and “0” might vary significantly over time. One time there might be 5,000 “1” bits and another time there might be 9,000 “1” bits. The HTM region could convert this input into an internal representation of 10,000 bits of which 2%, or 200, are active at once, regardless of how many of the input bits are “1”. As the input to the HTM region varies over time, the internal representation also will change, but there always will be about 200 bits out of 10,000 active.
Numenta’s white paper states that, “Time plays a crucial role in learning, inference, and prediction.” We’ll see the truth in this when we compare the HTM with purely feed-forward ANNs.
HTM networks are trained with, and form predictions about, time-varying input-data. We should have good reason to believe that the data contains some type of temporal pattern, otherwise it is simply noise (like static on the radio). Too many unrelated temporal patterns in the data-stream can also lead to poor results (students with ADHD and poor study habits know this very well).
We’ve been dancing around the technical details for a while now, so let’s have a closer look at how HTMs create memories and form predictions.
Recall that each HTM region contains a three dimension grid of cells, and each cell can be either on or off (for various reasons). The cells are grouped in vertical columns, and all the cells in a column get the same feed-forward input (either directly from the data, or the output from a lower HTM region). The input, as mentioned previously, is converted to a sparse distributed representation, and then each column gets a unique subset of that input (usually overlapping with other columns, but never the exact same subset). Cells also receive lateral input from other columns of cells.
Which cells get activated within a column depends on a variety of factors, and the use of columns allows the HTM to create temporal contexts. The white paper explains:
By selecting different active cells in each active column, we can represent the exact same input differently in different contexts. A specific example might help. Say every column has 4 cells and the representation of every input consists of 100 active columns. If only one cell per column is active at a time, we have 4^100 ways of representing the exact same input. The same input will always result in the same 100 columns being active, but in different contexts different cells in those columns will be active.
Which cells in a column become active depends on the current activation state of those cells:
When a column becomes active, it looks at all the cells in the column. If one or more cells in the column are already in the predictive state, only those cells become active. If no cells in the column are in the predictive state, then all the cells become active. You can think of it this way, if an input pattern is expected then the system confirms that expectation by activating only the cells in the predictive state. If the input pattern is unexpected then the system activates all cells in the column as if to say “the input occurred unexpectedly so all possible interpretations are valid”.
Real neural networks contain inhibitory signals as well as excitatory ones. The same concept is applied in HTM regions as part of the lateral input that cells receive from their neighboring columns:
The columns with the strongest activation inhibit, or deactivate, the columns with weaker activation. (The inhibition occurs within a radius that can span from very local to the entire region.) The sparse representation of the input is encoded by which columns are active and which are inactive after inhibition. The inhibition function is defined to achieve a relatively constant percentage of columns to be active, even when the number of input bits that are active varies significantly.
Lateral input can inhibit as well as excite cells, and this is how HTM regions form predictions:
When input patterns change over time, different sets of columns and cells become active in sequence. When a cell becomes active, it forms connections to a subset of the cells nearby that were active immediately prior. These connections can be formed quickly or slowly depending on the learning rate required by the application. Later, all a cell needs to do is to look at these connections for coincident activity. If the connections become active, the cell can expect that it might become active shortly and enters a predictive state. Thus the feed-forward activation of a set of cells will lead to the predictive activation of other sets of cells that typically follow. Think of this as the moment when you recognize a song and start predicting the next notes.
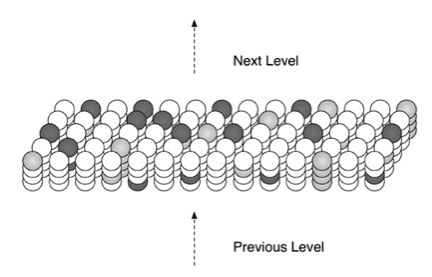
Figure 1.3: At any point in time, some cells in an HTM region will be active due to feed-forward input (shown in light gray). Other cells that receive lateral input from active cells will be in a predictive state (shown in dark gray).
The influence one cell has on another is moderated by the strength of the a virtual synapse between, which can have a decimal value between 0 and 1. For additional details, please see the white paper.
As mentioned to previously, HTM regions are used to map noisy data to more stable concepts. Another way to state that is: regions extract temporal patterns out of their input.
In this section I will use the phrase “primitive ANN” to refer to feed-forward networks that do not have contain cycles between cells.
Primitive ANNs do not take into account time, and this severely limits the types of patterns they are capable of recognizing. They do terrible job of anticipating future events because they don’t support a contextual temporal model.
What does that ____?
Precisely! I see that you understand perfectly. ☺
Those fluent in modern English can probably fill in the blank without much trouble, or at least are capable of narrowing down the possibilities to a handful of words.
To illustrate the difference between temporal patterns and those handled by primitive ANNs, consider how you might have reacted had I instead written:
That ____?
Now it is much more difficult to predict what belongs in the blank. This is due to the lack of prior context. Human senses such as touch, vision, and hearing, absorb and react to symbols (input) in a sequential manner. The sequence these symbols present themselves in usually results in predictable patterns. We can predict the word that belongs in the first blank simply because our brain has heard it stated so many times after the words “What”, “does”, and “that”.9
Primitive ANNs do not use any sort of temporal context to make predictions. Instead, they treat input as chunks of raw data that is then mapped directly to an output without consideration for the order in which the data arrived. The output depends entirely on the ANN’s training data and error-correction algorithms.
Therefore, a primitive ANN processes “What does that” in a single gulp, treating it no differently than it would a single word.
Another consideration is efficiency. Numenta’s white paper points out that hierarchies result in less training time for the network “because patterns learned at each level of the hierarchy are reused when combined in novel ways at higher levels.” While I’m not 100% certain (as I did not have the time to test and compare implementations), I suspect that hierarchy accounts for only part of the improvement in efficiency. I think a hierarchy of HTMs would outperform an “equivalent” hierarchy of primitive ANNs because of the memory-efficiencies that temporal contexts provide.
Long short term memory (LSTM) refers to a type of recurrent neural network (RNN) first described in 1997 by Sepp Hochreiter and Jürgen Schmidhuber.10
RNNs have the capability of processing and interpreting temporal sequences unlike the feed-forward networks we just discussed. They accomplish this through loop-back connections among the cells within the network, giving their memory the capacity to process arbitrary sequences of data.
Of the various types of RNNs out there, the LSTM produces some of most the impressive results. Most other types of RNNs are not able to handle long pauses between events in the input data (for example, a period of silence when someone is talking). The LSTM does not have this limitation. Felix Gers thesis explains: 11
The [LSTM] algorithm overcomes this and related problems by enforcing constant error flow. Using gradient descent, LSTM explicitly learns when to store information and when to access it.
In Spatio–Temporal Memories for Machine Learning: A Long-Term Memory Organization, researchers Starzyk and He took inspiration from both the LSTM and HTM to create their own hierarchical neural net based on interconnected long-term memory (LTM) cells: 12
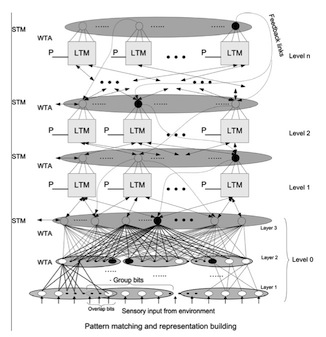
Figure 2.1: Overall LTM architecture.
I think a comparison of these two approaches deserves more attention and is something that I’d like to research further. I am also interested in reading additional material on this topic, so please, don’t be a stranger and feel free to send relevant material my way, I’d greatly appreciate it!
Surprisingly, the first major difference to jump out at me between the HTM and LSTM had nothing to do with algorithms or their respective topologies. Instead, it was the potent stench of dry, lifeless academic language wafting out of all of the documentation I could find on the LSTM that left a most profound impression on me. Indeed, the time I spent reading Ph.D. theses and papers from IEEE journals represented one of the least enjoyable parts of my research purely on account of the terrible prose. Regardless of what some might believe, Universities do not bundle academic degrees with a license to carry a rotting right-hemisphere. The guilty tend to cling to argumentum ad populum as their sole defense. In a just universe, they’d still be working through secondary school.
On the other hand, I have to commend academics for being team players, a concept that appears somewhat foreign to Numenta. Whereas all of the academic papers I read contained countless13 references and citations to other work in the field, the same could not be said of any of Numenta’s. None of the three Numenta papers on the HTM 14 15 16 contain anything resembling a references section acknowledging the authors of prior work upon which their ideas are based.
The academics, for their part, cited Hawkins’ work where appropriate.17
From my research I’ve concluded that, at least for me, the HTM and its corresponding learning algorithm(s) warrant further research, as they appear to be very useful and powerful tools for prediction, modeling real-world data, and creating artificial intelligences.
Also, software should not be patentable.18 19 20 21 22 The practice should be abolished immediately for the good of mankind and whomsoever disagrees with me on this owes me $1 billion in royalties because I patented the concept of being an asshole.
Comments on reddit or my blog.
Greg Slepak refers to a sometimes-conscious entity whose primary public activities some recognize as ‘entrepreneurship’, ‘software engineering’, and ‘writing’. He taught himself C at age 12, and continued to learn other programming languages, with present favorites Clojure and newLISP. During his freshman year as an undergraduate at UF, he joined CIMAR and wrote the High Level Planner for UF’s entry to the 2007 DARPA Urban Challenge. In 2008 he founded Tao Effect LLC as part of an effort to make data encryption more user-friendly.
This is a living document and future updates are a significant possibility. Notifications of updates will be posted to my twitter account, and possibly to my blog as well.
| Version | Date | Comment |
|---|---|---|
2.0.0 |
September 14, 2013 |
Changed title of paper. Replaced “Numenta’s Unethical Behavior” with “Numenta’s Commendable Behavior” because Numenta updated the agreement. Updated many related sections. |
1.0.1 |
August 28, 2013 |
Minor edits. |
1.0.0 |
August 26, 2013 |
Document first published online. |
I’m very much aware of the horrific state of this section, and hope to clean it up a bit in a future update. If you’d like to help me de-wikifiy the citations you are most welcome to contact me with links to better sources.
I would like to thank Andrea Devers for helping me edit and proofread this document, and Bob Jesse for his feedback.
https://en.wikipedia.org/w/index.php?title=Hierarchical_temporal_memory&oldid=567124697↩
https://en.wikipedia.org/w/index.php?title=Hierarchical_temporal_memory&oldid=567124697#Similarity_to_other_models↩
https://en.wikipedia.org/w/index.php?title=Linus_Torvalds&oldid=569095816↩
Requiring commas and periods within quotes (when they were not originally there) is an archaic and illogical practice that appears to have been invented as a hack to get around ancient printing problems. Its use in modern English is therefore an idiotic anachronism and should be abolished. If you see anyone doing it please be sure to forward this link to them. Raising hell about the matter is entirely up to you. I personally encourage it.↩
S. Hochreiter and J. Schmidhuber. Long short-term memory. Neural Computation, 9(8):1735–1780, 1997.↩
Starzyk, He Spatio-temporal memories for machine learning: a long-term memory organization.. See page 769 in “IEEE TRANSACTIONS ON NEURAL NETWORKS, VOL. 20, NO. 5, MAY 2009”.↩
Actually, there were counted.↩
Starzyk, He Spatio-temporal memories for machine learning: a long-term memory organization.. See page 769 in “IEEE TRANSACTIONS ON NEURAL NETWORKS, VOL. 20, NO. 5, MAY 2009”.↩
http://www.forbes.com/sites/reuvencohen/2013/05/08/new-zealand-government-announces-that-software-will-no-longer-be-patentable/↩
http://www.burgess.co.nz/law/why-software-should-not-be-patentable-the-academic-approach/↩
http://www.tonymarston.net/php-mysql/software-patents-are-evil.html↩
http://www.javaworld.com/javaworld/jw-03-2012/120316-open-sources.html↩